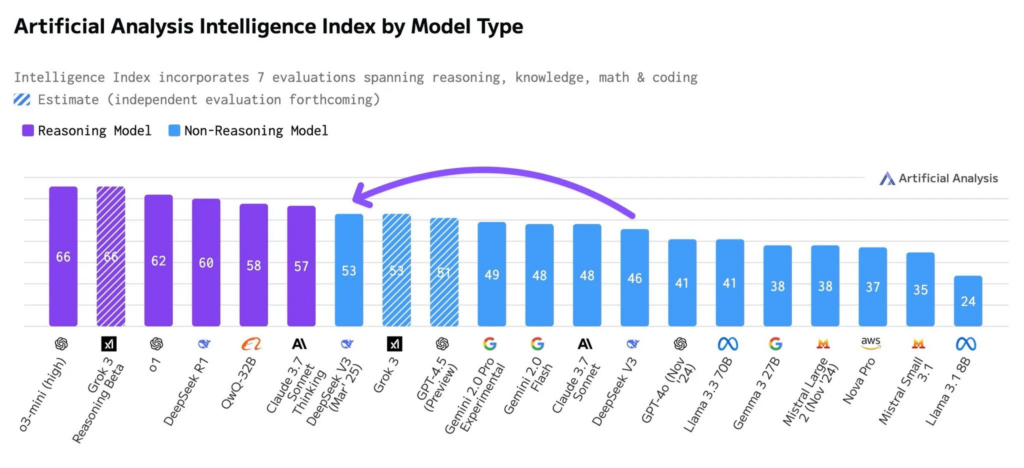
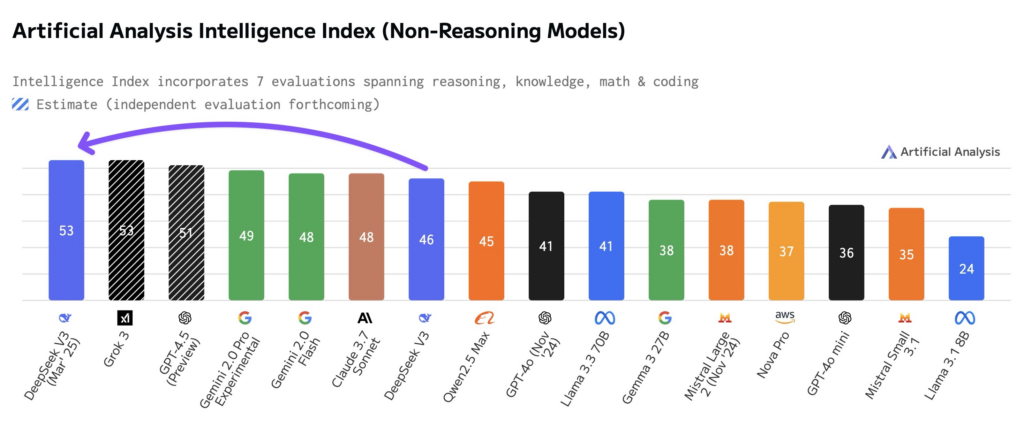
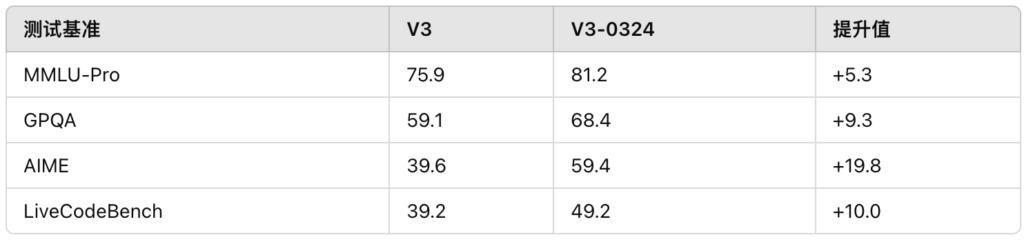
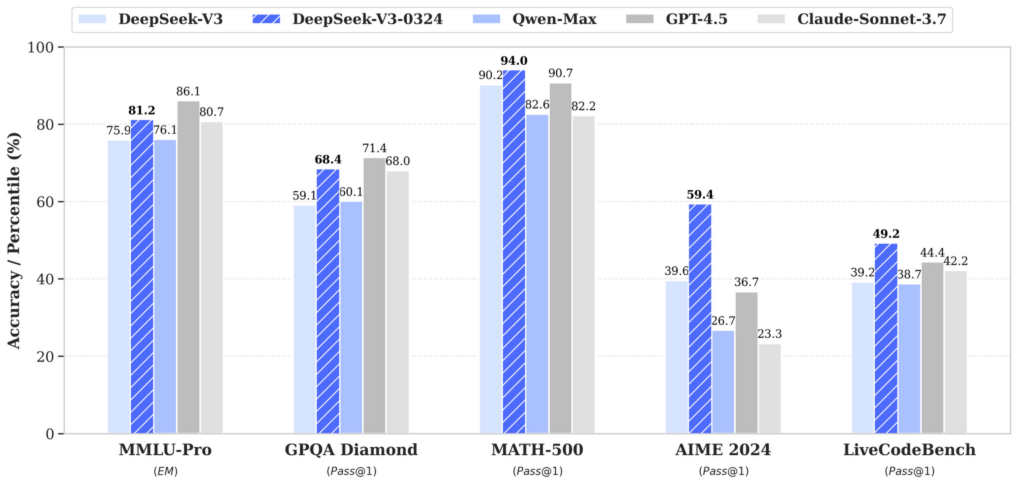
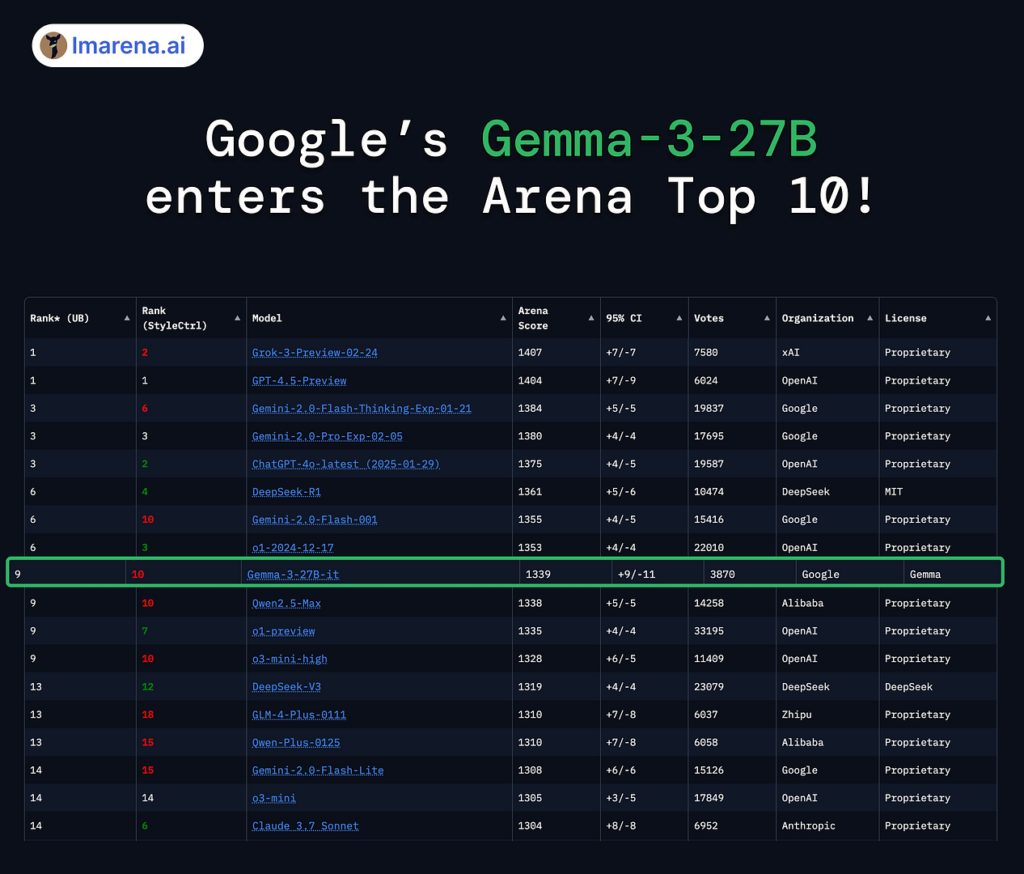
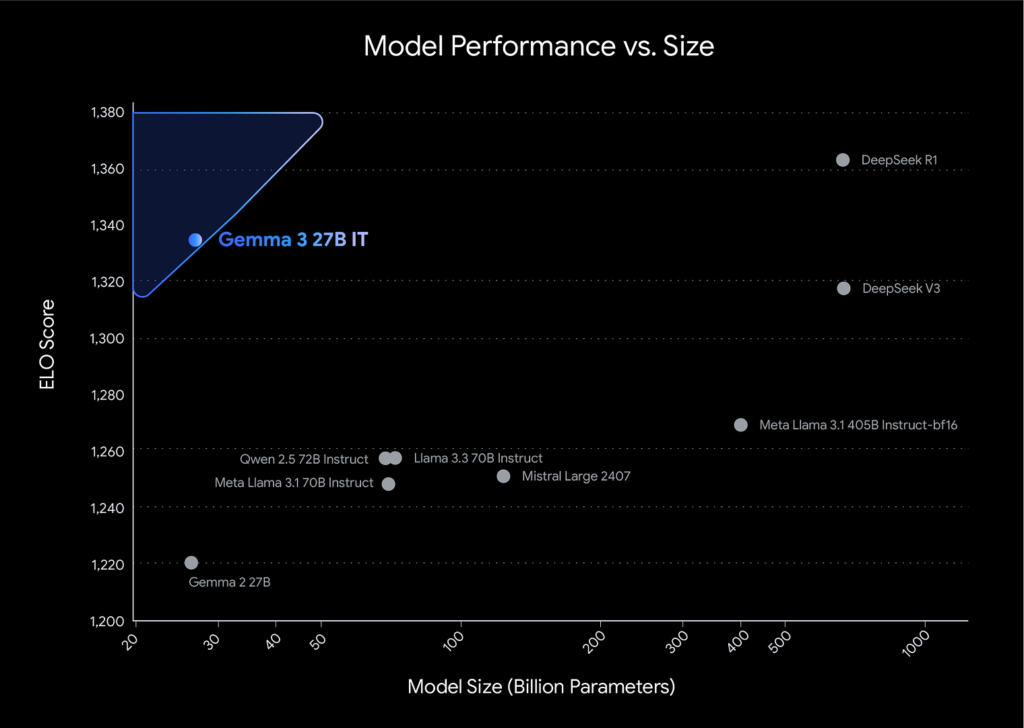
Google 发布 Gemini 模型的最新更新,推出 Gemini 2.5 Pro Experimental 版本
这一版本被描述为 Google DeepMind 迄今为止最智能的模型,强调其“思考”能力(thinking capabilities)的突破,旨在提升复杂问题解决能力和回答的准确性。
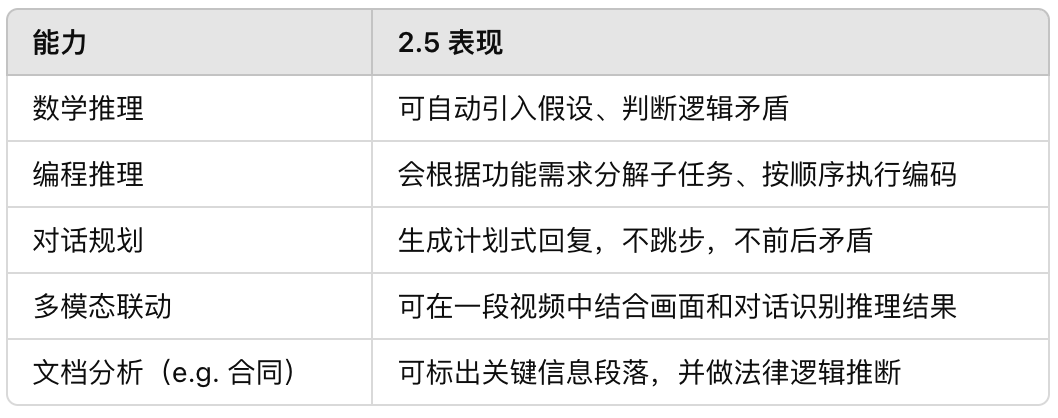
Thinking Model(思考型模型)
- 大幅提升 逻辑推理、编码生成、复杂任务处理能力
- 在多个领域标准评估中取得 SOTA 成绩
Gemini 2.5 的“思考能力”(Thinking Capabilities)
- 不只是分类或预测
- 而是:
- 分析信息 → 推理过程 → 得出结论 → 做出判断
- 包括:
- 上下文理解
- 多步逻辑推理
- 细节整合与假设检验
🔄 技术路径
- 继承自 Gemini 2.0 的 Flash Thinking 技术
- 在此基础上,2.5 通过:
- 更强大的基础模型结构
- 更完善的后训练机制(post-training) 实现推理力的质的飞跃

📐 上下文窗口扩大
- 当前支持 1M tokens 上下文,即 100 万 tokens
- 已测试支持 2M tokens(200 万)
- 可处理整本书、整站网页代码、视频字幕、复杂长表格等
- 上下文中的图片、语音也可以一起分析推理
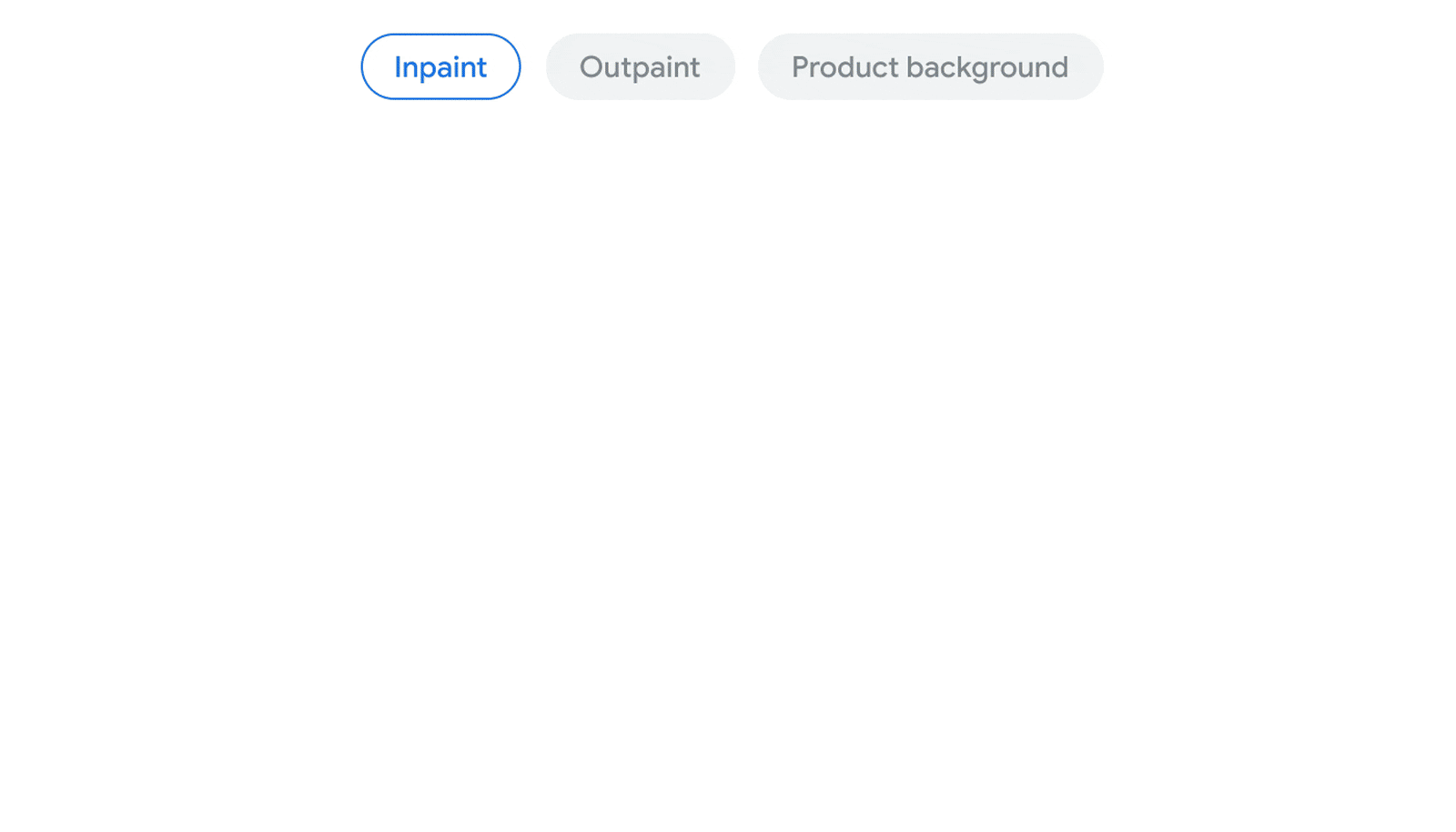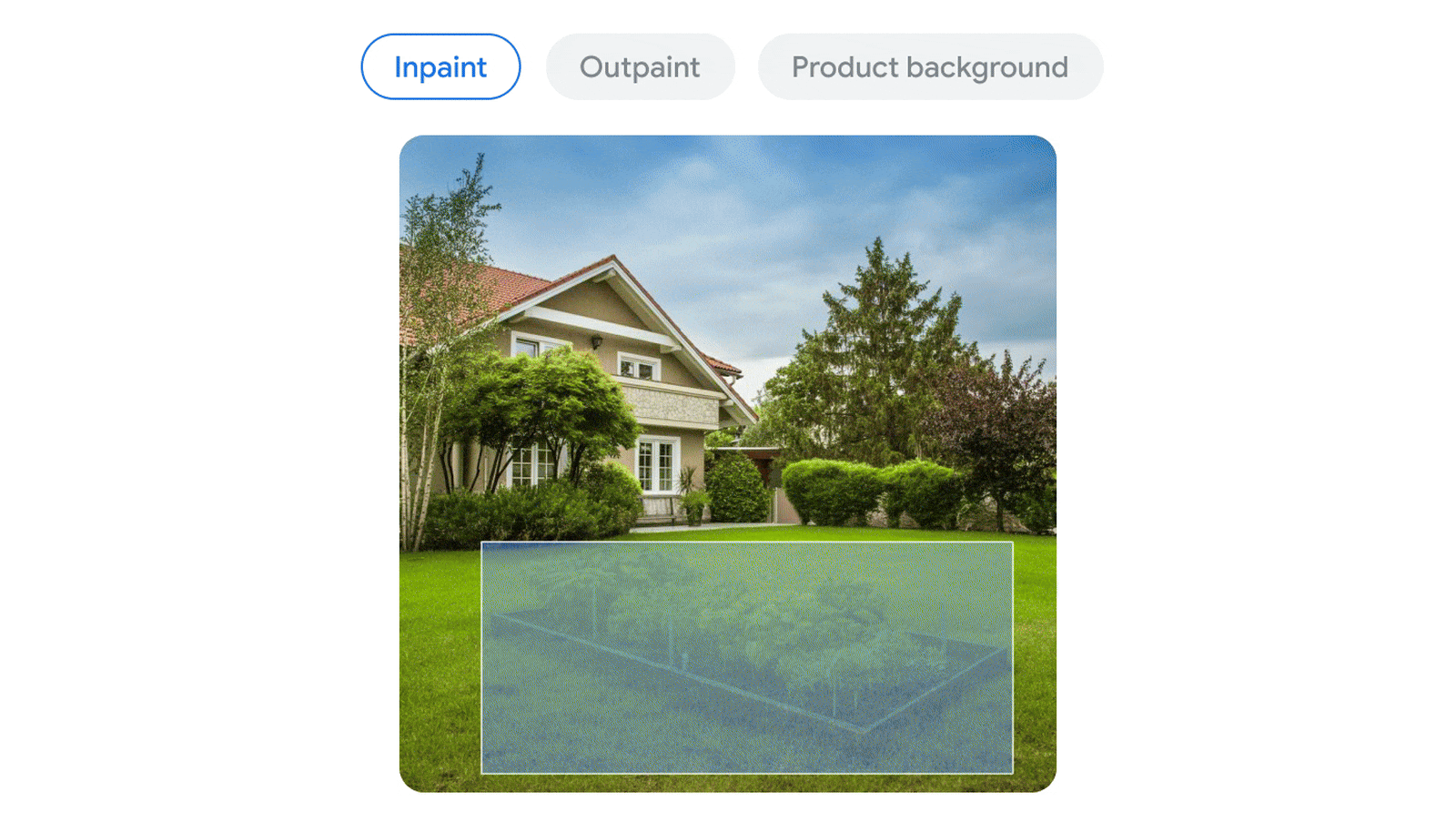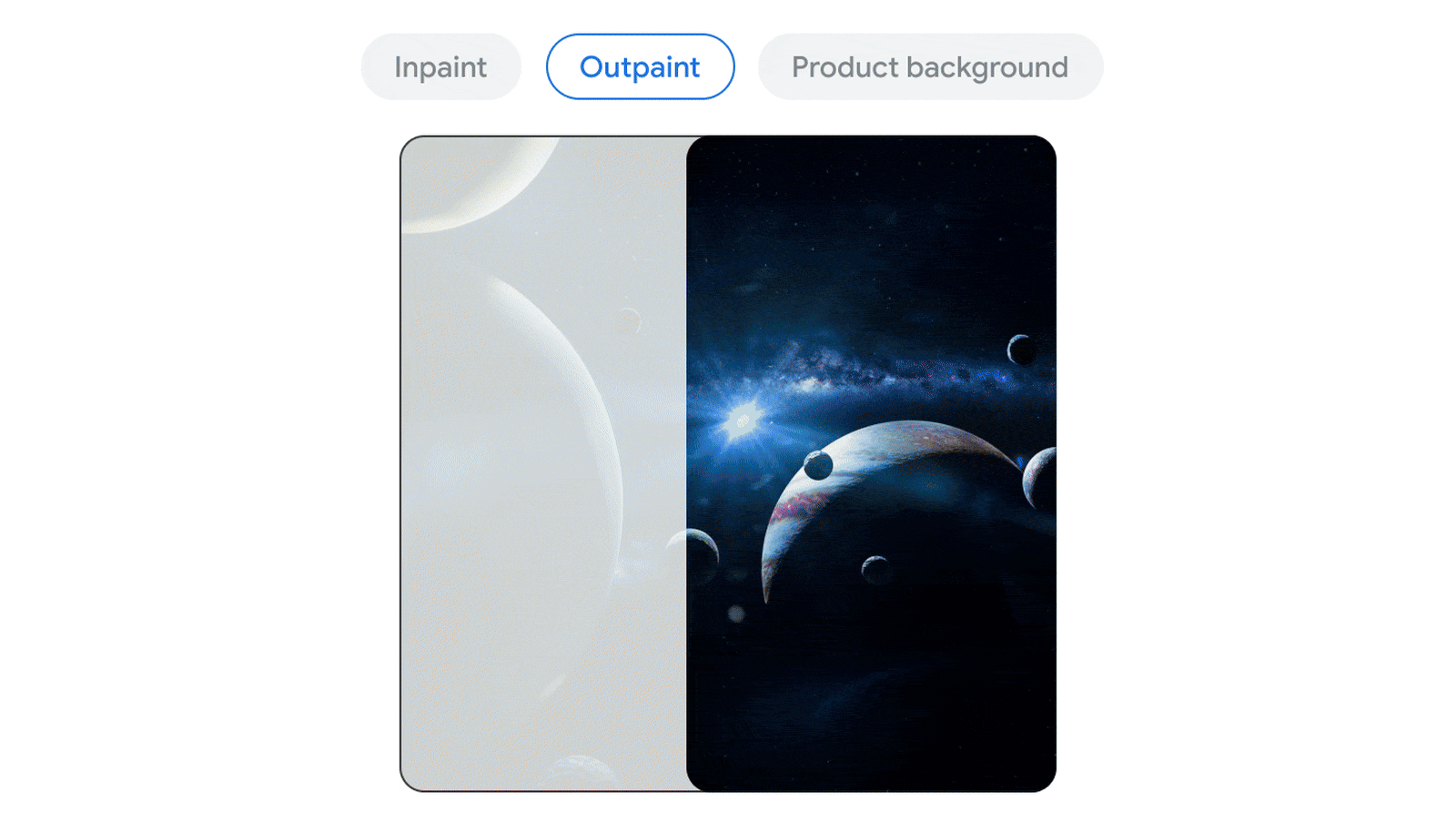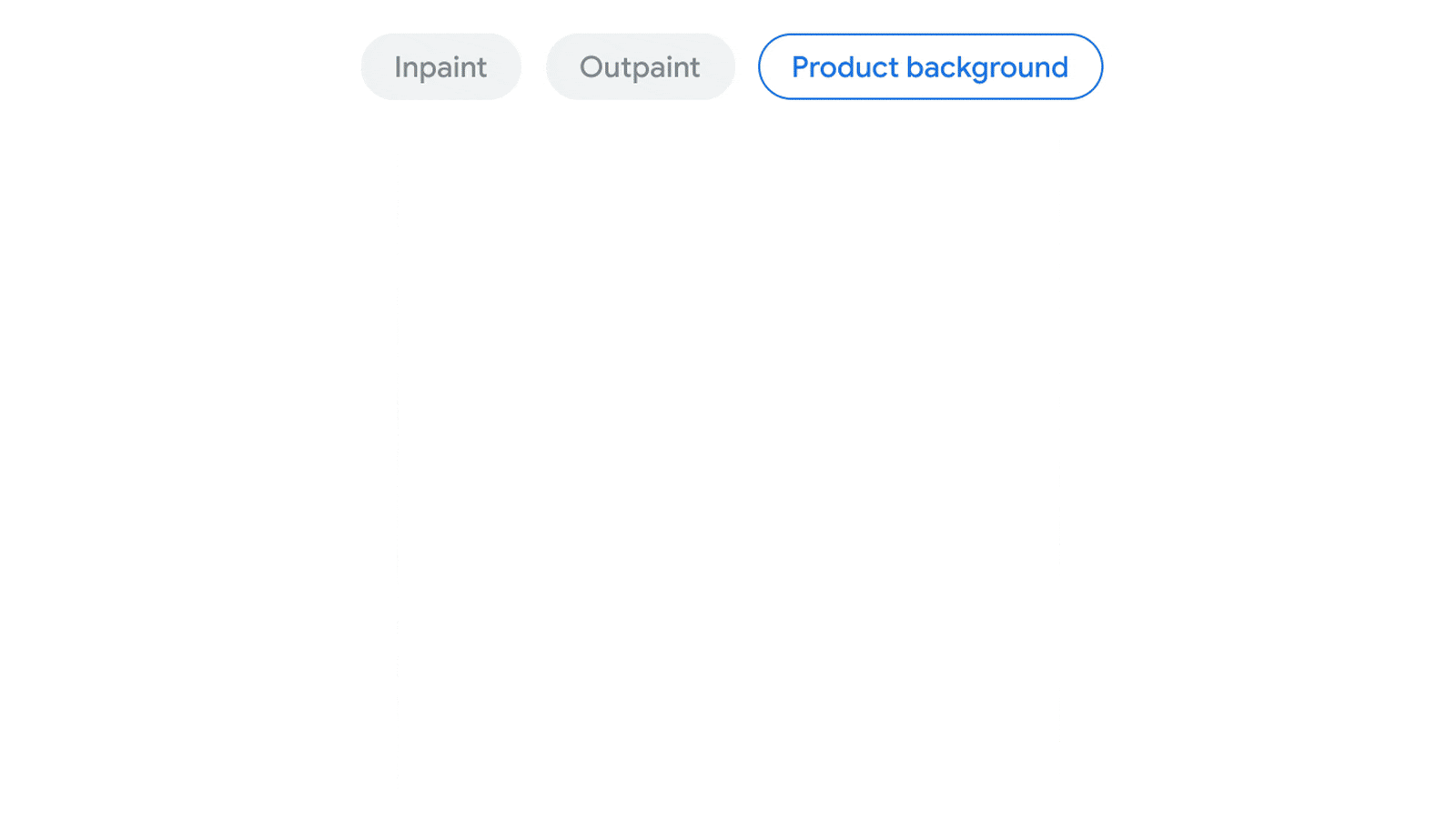
🖼️ 多模态原生支持(非外挂)
- 原生支持:
- 文本
- 图片(含图表、草图、照片)
- 视频(含字幕、动作识别、语义理解)
- 音频(如语音合成/识别)
- 代码(整 repo 分析)
- Gemini 2.5 并非“图像处理外挂模型”,而是统一架构共享注意力机制,实现图-文-音-码同源协同处理。
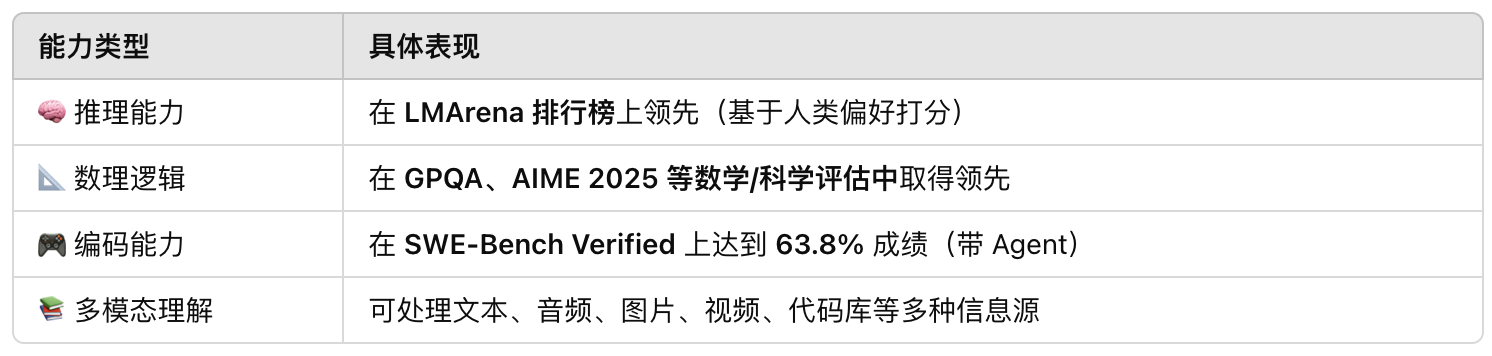
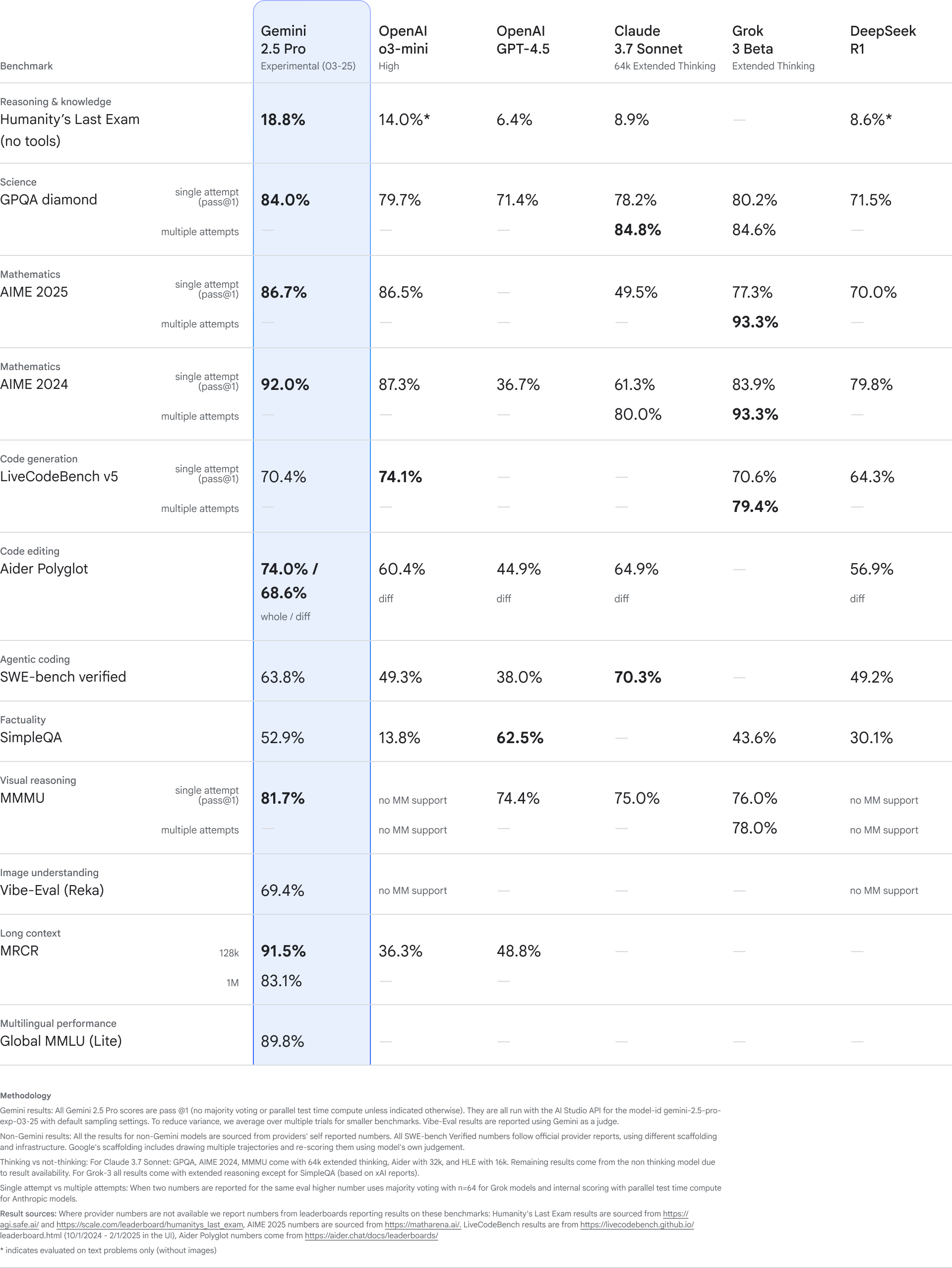
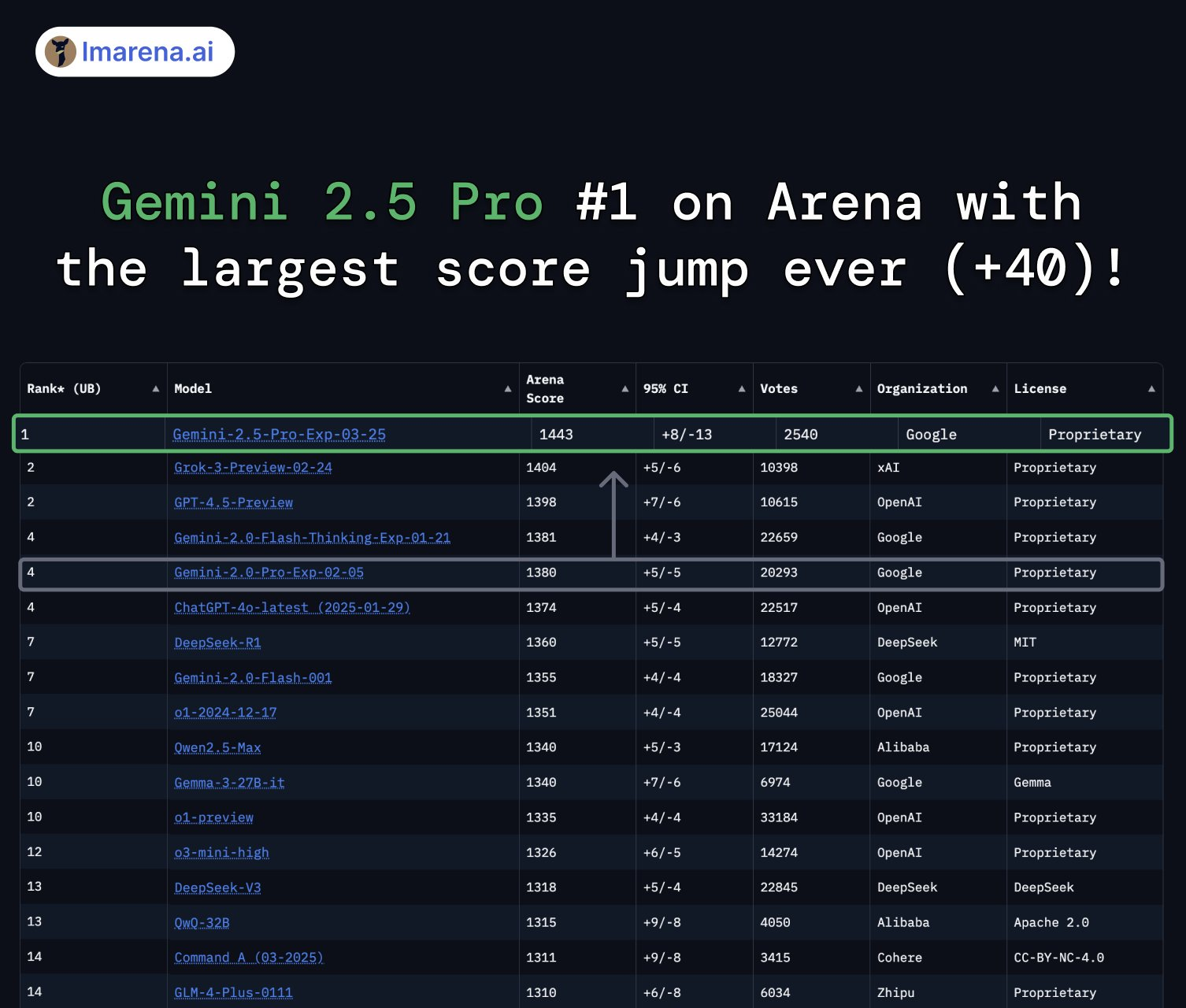
模型评估成绩
Gemini 2.5 在以下方面超越前代:
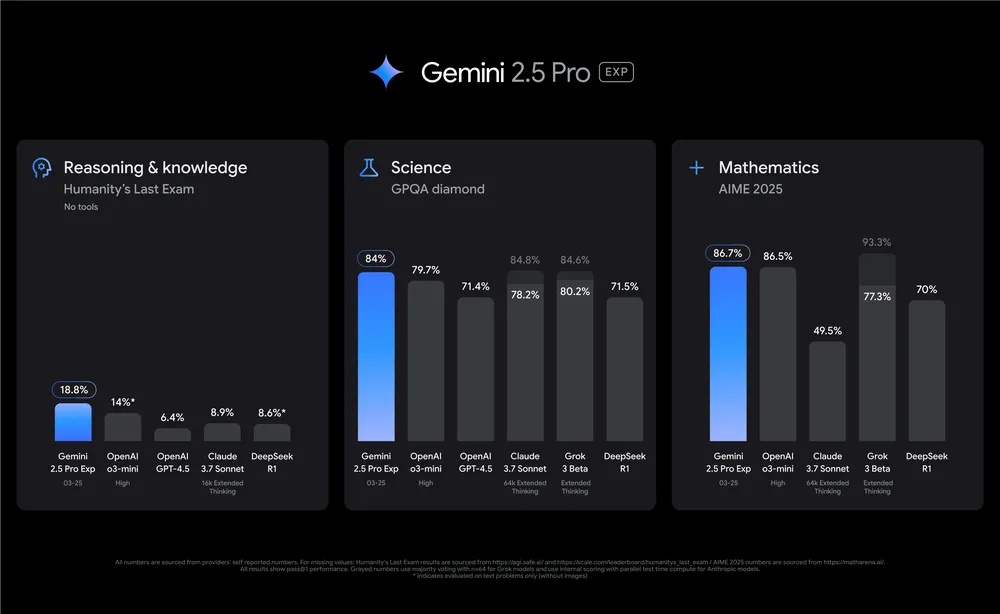
🧠 推理能力表现
- 在 Humanity’s Last Exam(测试 AI 在人类高阶知识推理的能力)中,Gemini 2.5 创下 18.8% 得分,为 无工具模型中全球最强。
- 在 LMArena 上,获得当前 人类偏好最高分
💻 代码能力表现
- 在 SWE-Bench Verified(真实软件修复任务)中:
- Gemini 2.5 使用思考代理,得分高达 63.8%,表现优于所有已发布模型,包括 Claude 3.5、GPT-4o 和 DeepSeek 等
- Gemini 2.5 代码能力包括:
- 分析错误提示 → 修改源码 → 调整测试脚本
- 根据自然语言 issue 描述完成代码编辑任务
- 可执行包括多文件协调、依赖管理、模块接口匹配等复杂工程任务
多模态能力
- 支持处理:
- 文本、图像、视频、音频、代码、对话等输入
- 在 Gemini 1.5 的基础上进一步提升多模态理解与融合效果
📊 其他任务能力
模型架构升级亮点(技术部分)
🏗 架构继承自 Gemini 1.5
- Transformer + Mixture of Experts(MoE)架构
- 原生支持多模态 token 表达(图像、视频、音频作为 token 流输入)
🔍 新增优化点
- 强化长上下文建模能力
- 当前支持 100 万 tokens 上下文
- 即将推出 200 万 tokens 版本,匹配 Claude 3.5 的水准
- 改进的 Flash Attention v2 + KV 缓存结构
- 提升长序列处理效率
- 保持对 prompt 中长程依赖的理解
- 代理结构对接 Agentic Planning
- Gemini 2.5 已能支持 step-by-step planning
- 可做任务计划拆解 → 工具调度 → 回收结果 → 总结优化
研发策略:“思考能力优先”的新训练范式
- DeepMind 的研究方向正在从:
- 语言能力 → 多模态能力 → 思考能力(reasoning first paradigm)
- 具体策略包括:
- 对推理路径建模(step-wise target modeling)
- 思维链标注数据构建(CoT + debates + plans)
- 扩展式对话记忆调度系统(contextual memory router)
- 过程反馈学习(process supervision)
- 这意味着:不再只是关注“最终答案对不对”,而是要看“怎么得出的”,是否像人一样思考。
📈 Google 未来三步走
- “思考力”标准化:每代 Gemini 模型都将内建结构化思维能力
- Agent 系统扩展:发展为具备持续记忆、环境交互能力的 AI 系统
- 结合 Google 生态能力:
- DeepMind + Search + Workspace
- 代码 + 文档 + 视频 + Gmail 一体智能助理
开发人员和企业现在可以开始在 Google AI Studio 中试用 Gemini 2.5 Pro,Gemini Advanced 用户可以在桌面和移动设备的模型下拉列表中选择它。它将在未来几周内在 Vertex AI 上提供。
有需要的同学可以联系客服
付款与货币结算:本产品支持支付宝、微信 等支付。(支付宝若付款页面没显示支付宝,请刷新重启网页)
发货与售后:所有可下单的产品均有现货,付款成功后,系统将自动发货至您的邮箱。如需了解更多关于我们的服务与售后政策等信息,请查看我们的服务条款和隐私政策。
产品来源: 本平台通过渠道优势采购获取,确保用户使用的API的安全性与稳定性。
付款与货币结算:本产品支持支付宝、微信 等支付。(支付宝若付款页面没显示支付宝,请刷新重启网页)
发货与售后:所有可下单的产品均有现货,付款成功后,系统将自动发货至您的邮箱。
客服:Telegram :@dogapis X: @dogapis WhatApps:+852 51405897
如需了解更多关于我们的服务与售后政策等信息,请查看我们的服务条款和隐私政策。